






Automatisk komposition med autonoma instrument

En väsentlig aspekt av kreativitetens psykologi är att släppa taget om den medvetna kontrollen över den skapande processen. I komposition har det länge satts i system genom tillgripandet av olika slags orakel, eller metoder för att mer eller mindre systematiskt delegera sina val. I sin mest konsekventa form innebär det algoritmisk komposition. I och med att rötterna till algoritmisk komposition kan sökas i formaliserade kompositions- och variationstekniker, kan man finna exempel på sådant delegerande av val genom hela den västerländska musikhistorien.
Autonoma instrument har mycket gemensamt med algoritmisk komposition vad gäller metod och raison d'être. Det rör sig om en form av komposition genom ljudsyntes, där processer på hög nivå uppstår som emergenta fenomen ur regler eller mekanismer som verkar på låg nivå. Begrepp som självorganisering, emergens, komplexitet och autonoma system är praktiskt taget oskiljaktiga utan att för den skull vara synonyma. Återkoppling (feedback) och ickelinearitet förekommer i många sammanhang där man talar om emergens och självorganisering. Det är alltså ingen tillfällighet att autonoma instrument för att göra skäl för namnet praktiskt taget alltid har med återkoppling att göra, om det så är i form av akustisk rundgång eller mera indirekta former.
Autonomi och kompositionsprocesser
Det talas mycket om 'affordances' (oppfordringsegenskaper på norska, men vem orkar skriva ett så långt ord?) i förbindelse med nya elektroniska eller digitala instrument. Om möjligt talas det ännu mer om frånvaron av affordance i dåligt utformade digitala instrument. Redan vid en första blick ser vi flera saker man skulle kunna göra med en violin, låt säga att knäppa på strängarna, stämma om den, råka sätta sig på den, pantsätta den ... och motsvarande med andra akustiska instrument. En synt har kanske tangenter att spela på och saker man kan trycka och skruva på. Det är uppenbart vad man kan göra med synten. Men vem skulle få för sig att tejpa fast en av tangenterna och låta det vara hela kompositionen? En minimalist, förstås.
Med autonoma instrument menar jag sådana system som man inte interagerar med direkt medan de genererar ljud. Det finns en historisk precedens för den typen av musikskapande - historisk också i betydelsen att den inte längre besitter nyhetens behag - nämligen ljudsyntes genom syntesspråk i släkt med MUSIC N. Traditionellt har dessa språk (utvecklade av Max Matthews på 1960-talet) haft en uppdelning i en 'orkester' med instrumentdefinitioner och en notlista som anger tidpunkter och parametervärden för instrumenten. Uppdelningen i instrument och notlista (eller partitur) är flexibel, men för också med sig att man föreställer sig att musiken är uppbyggd av enskilda noter. Begränsningen försvinner om man inte inskränker sig till notbilder som är typiska för partitur avsedda för musiker. Noterna kan vara några millisekunder långa, förekomma i miljontal och tillsammans bilda en granulär svärm av ljud, eller man kan låta en enda not utgöra hela kompositionen, oavsett hur länge den varar.
Minimalistiska stycken som bara består av en enda ton finns det flera av (t.ex. av La Monte Young), men notbegreppet i MUSIC N är förstås långt mera flexibelt. En not behöver nämligen inte motsvara en ton. Man kan låta syntesalgoritmen stå för förändringar över tid, så att en enda not kan motsvara långsträckta komplexa musikaliska processer.
För att sådana förlopp ska bli musikaliskt komplexa krävs det bland annat variation över flera olika tidsskalor parallellt. Det finns en del grundläggande strategier för hur man kan skapa sådana variationer över flera tidsskalor:
1) Stokastiska kontrollsignaler som uppdateras olika ofta.
2) Överlagring av periodiska förlopp med periodlängd som inte går jämt upp.
3) Självreglerande återkopplade system (kaotiska system).
Dessutom kan dessa tre metoder kombineras i olika hybridformer. Ett exempel på metoden med stokastiska signaler är Xenakis stycke S.709 realiserat med programmet GENDY. Periodiskt återkommande material med periodlängder som fasar ut har använts bl.a. av Brian Eno i Music for airports. Exempel på återkopplade system kommer jag tillbaka till. Denna strategi, dvs icke-interaktiva instrument som skapar storskaliga ljudförlopp utan att explicit förhålla sig till en notnivå, är typisk för autonoma instrument.
Autonomins gränser
Autonoma instrument kräver någon form av automatisering, vilket innebär att de måste vara digitala eller analoga system. Vad vore kvar av de autonoma instrumenten om elektriciteten hade varit avstängd? Man kan i och för sig tänka sig mekaniska autonoma instrument. Det tycks innebära att de är evighetsmaskiner, för om de ska vara strikt autonoma måste de försörja sig själva med den energi de förbrukar.
(Den svenske science fiction-entusiasten Sam J. Lundvall har skrivit en roman, Bernhards magiska sommar om jag minns rätt, som utspelar sig en sommar i Stockholm där djävulen figurerar i en biroll. Det visar sig att han har en samling beslagtagna evighetsmaskiner - logiskt nog finns det en förklaring till varför vi aldrig ser några som fungerar!)
I avsaknad av verkliga evighetsmaskiner får man acceptera att autonoma instrument får sin energi utifrån. Det skulle kunna vara som i Ligetis Poème Symphonique, där metronomerna dras upp och laddas med mekanisk energi och där stycket varar så länge den energin omsätts i pendling och tickande. På samma sätt som med autonoma instrument interagerar man inte med metronomerna under styckets gång. 'Look ma, no hands!' Gott och väl, men det ska mera till.
Ett annat kännetecken för autonoma instrument är deras förmåga att åstadkomma ljudförlopp som inte har planerats i detalj i förväg, eller som inte helt kunde ha förutsetts. I annat fall kunde man räkna en CD-spelare som ett autonomt instrument.
Det är förstås meningslöst att tala om absolut autonomi. Det finns bara autonomi i förhållande till något annat. Mekaniska såväl som elektriska instrument måste ha sin energitillförsel. Det är så uppenbart att man nästan har rätt att vara blind inför detta faktum. Autonoma instrument fordrar en separation gentemot tonsättaren. De ska inte stå under ens fulla kontroll. Men det samma kunde man säga om kombinationen av en oerfaren musiker och ett svårspelat instrument - och det är en helt annan historia.
Om man alltså ska avstå från att spela på instrumentet så tycks man vara hänvisad till någon form av objets trouvées. Strategin vore därför inte helt olik lomografens tillfälligt knäppta bilder, bokstavligen skjutna från höften, eller fältinspelningar gjorda med en kvarglömd bandspelare som aktiveras av ljud och stänger av sig själv när inget av intresse händer. När man väl har bestämt sig för vilken algoritm som ska användas i det autonoma instrumentet kan man se på resultatet som ett funnet objekt. Resultatet är här en ljudfil som det autonoma instrumentet genererar. Men varifrån kommer algoritmen?
Att använda existerande algoritmer eller dynamiska system till ljudsyntes eller till någon form av generativ musik är mera besläktat med sonifiering än med autonoma instrument. Då blir det faktiskt möjligt att använda algoritmer som funna objekt. Men strategin med autonoma instrument är att skapa algoritmen själv, för det specifika syftet att få den att generera en acceptabel ljudfil.
Estetiska preferenser
Dilemmat är kvalitetskontroll. Måste man inte abdikera från sin personliga smak om man ska överlåta skapandet åt maskinen? Nu är det förvisso så att man inte överlåter så väldigt mycket, bortsett från enorma mängder med numeriska operationer, till maskinen. Framförallt bibehåller man sin status som skaparen av ljudfilen, på samma sätt som fotografen av sitt foto eller journalisten av sin intervju. Trots det uppstår det alltså en kinkig situation om man försöker komponera god musik med hjälp av autonoma instrument. Man måste ha preferenser. Då kan man programmera sina autonoma instrument på ett sätt som får dem att låta bra enligt de preferenserna man har. Naturligtvis är de motsträviga just i den grad de är autonoma - det finns de mest besynnerliga spärrar för att förbättra specifika aspekter av kompositionen. Alternativt finns det inga spärrar alls för att styra resultatet i önskad riktning, men då är man, per definition, över i något som inte längre har med autonoma instrument att göra.
Det är inte alls klart hur komponistens preferenser ledsagar den skapande processen; själva begreppet om preferenser är diffust. Fråga en bildkonstnär vilken som är hennes favoritfärg - där har vi en elementär preferens - eller fråga en tonsättare om favoritton eller en matematiker om lyckotal; kanske finns det någon som kan svara på det, men för många är sådana frågor meningslösa. Nästa nivå är relationer mellan två färger, intervall mellan två toner. Arbetet med autonoma instrument presenterar en annan typ av val. Man får så att säga ett arbetsutkast från det autonoma instrumentet, en skiss till en fullständig komposition eller bara brottstycken av mer eller mindre användbart material. Det finns olika förhållningssätt till detta material; man kan betrakta det som den färdiga produkten, eller som råmaterial som ska gå igenom en längre process av redigering. Men låt säga att vi ska använda ljudfilen som den är, just i det skicket den kommer ut ur det autonoma instrumentet. Då finns det oöverskådliga mängder av möjligheter för hur den kan låta, speciellt om den har en viss längd. I den situationen talar vi alltså om preferenser: ändrar man någon parameter i det autonoma instrumentet så får man en annan ljudfil, och genom att successivt ändra en parameter kan man få familjer av ljudfiler som är mer eller mindre besläktade. De särskiljande dragen kan vara globala, dvs de kan ge utslag genom hela förloppet från början till slut. Hur akustiska parametrar inverkar på perceptionen av klangfärg, tonhöjd och uppfattad ljudnivå har studerats och omsatts i syntesmodeller. Men här har vi att göra med en klass av syntesmodeller som har parametrar som inflätat i varann påverkar alla dessa dimensioner, och i tillägg också andra egenskaper på högre nivå, som kanske har med frasering eller storform att göra. Både storskaliga och småskaliga tidsförlopp kan stå under samma parameters influens, vilket gör det invecklat eller omöjligt att isolera olika aspekter och styra dem separat.
Estetiska preferenser är inte nödvändigtvis permanenta och stabila. När man arbetar med autonoma instrument och använder dem som en skisseringsapparat som (nästan) automatiskt kommer med förslag till ett nytt 20 minuters verk, så nöjer man sig kanske inte med första bästa förslag. Men (som Rosemary Mountain har påpekat rörande elektroakustisk komposition) medan man hör dessa förslag så kanske man glömmer vad det var man ville åstadkomma från början, ifall man över huvud taget hade någon idé (Mountain, 2001). Skisseringsmaskinen kan i princip komma med bättre idéer än man hade kunnat tänka ut själv, annars är det egentligen ingen vits med en sådan apparat. Och när den kommer fram med något man kan tänka sig att använda, men som man inte utan vidare hade kunnat tänka ut själv, har man inte då fått sina preferenser manipulerade en smula?
Arbetsprocessen kan skematiskt illustreras med två hissar, skisseringsapparaten är den ena och komponisten den andra. De lyfter i tur och ordning materialskisserna till nya höjder, som fungerar som avsatser från vilka den andre parten kan lyfta materialet vidare, tills det svävande i luften uppnår verkhöjd.
Fotnot om repertoar
Autonoma instrument var ingen etablerad term när jag började forska på dem, och har antagligen inte hunnit bli det heller. Därför kan man inte så lätt söka efter en repertoar av existerande verk för och med autonoma instrument. Det man kan göra är att argumentera för att olika stycken passar mer eller mindre bra in på beskrivningen, så att de kan sägas utgöra musik skapad med autonoma instrument. Det finns ändå ett nätverk av stycken som är familjebesläktade med varann, som ofta nämns tillsammans i olika översikter. En utgångspunkt kan vara återkopplade system (Sanfilippo & Valle, 2012). Andra nyckelord är cybernetik, komplexa system, emergens och självorganisering. När man hör ett eller flera av dessa begrepp anänvdas om ett stycke musik är det en god indikation på att där förekommer idéer besläktade med autonoma instrument.
Min lösning var att ta utgångspunkt i en besläktad term, semi-autonoma instrument, som ibland används för att beteckna vissa typer av interaktiva system som vanligtvis kopplar samman maskinlyssning med någon form av algoritmiskt genererad respons eller så att säga spontant genererat material. Några närmast kanoniska exempel är George Lewis Voyager och Agostino Di Scipios Hörbare Ökosysteme. Andra ganska bra exempel är Gordon Mummas Hornpipe (som är ett analogt interaktivt system), eller nätverksensembler som The League of Automatic Composers och senare The Hub, som knyter samman flera datorer som fördelar olika uppgifter sig emellan. David Tudors installationer i serien Rainforest och andra av hans stycken är också bra exempel på hur analoga elektroniska komponenter kopplas ihop i komplexa nätverk som uppvisar ett komplicerat beteende som säkert kan påverkas men torde vara svårt att styra.
Man får i dessa fall en situation där datorn (alternativt de analoga kretsarna) används som en improviserande partner som i viss mån kommer med sina egna musikaliska impulser - därav autonomin. Men i den typen av interaktiva system skulle en total autonomi innebära att datorn inte behövde reagera på vad musikern spelar, och då går man förstås miste om interaktiviteten. Att jag ändå vill se strikt autonoma instrument i relation till semi-autonoma instrument kan förklaras metaforiskt som följer: En ensam musiker, låt säga en flöjtist, spelar en ton och hör omedelbart att den är för hög, och anpassar sin embouchure därefter. Det är en blixtsnabb process som beror på en återkoppling från vad man hör till vad man gör, och från vad man gör till hur instrumentet låter. Mina autonoma instrument bygger på en likartad återkoppling. Den signal de genererar analyseras och signaldeskriptorer omvandlas till kontrollfunktioner som styr syntesparametrarna. Visserligen har jag inte försökt modellera hur musiker fungerar, det är bara det att återkoppling av det slaget är en väsentlig del av alla slags automatiserade självreglerande styrsystem. Och en musiker kan delvis förstås som ett självreglerande system lika mycket som ett autonomt instrument kan vara det.
Bristen på en repertoar av verk som man helt säkert kan hävda är producerade med autonoma instrument kan tyda på att det inte har varit en speciellt attraktiv strategi för musikskapande. Å ena sidan är interaktivt musikskapande vanligt, där improvisation kan spela en viktig roll. Å andra sidan finns hela den akusmatiska skolan, där fixerade verk utan musiker är den dominerande musikformen. I akusmatisk musik har det inte varit vanligt att i någon större omfattning överlåta produktionen av verket åt algoritmer. Även där det finns undantag är algoritmerna sällan goda exempel på autonoma instrument. Om man ska lyfta fram exempel som kan illustrera principen om autonoma instrument så är Xenakis Gendy-program och styckena realiserade med det kanske de mest övertygande.
Teknisk notis: FEFS (exkurs för nördar)
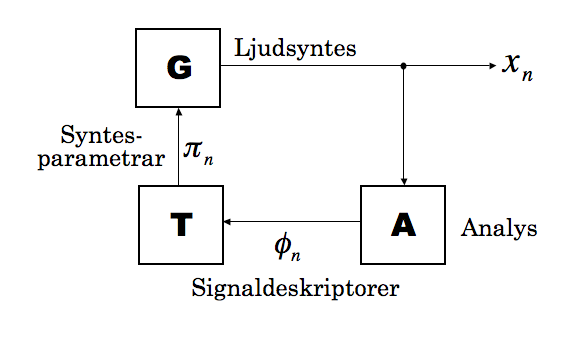
I min avhandling fokuserade jag på att utforska en speciell typ av återkopplade system som mig veterligen inte har studerats förr. Dessa system består av tre komponenter (se figur nedenfor): en signalgenerator (G), en analysmodul (A), och en omvandlare eller transformator (T). Namnet på sådana system är Feature Extractor Feedback Systems (FEFS).
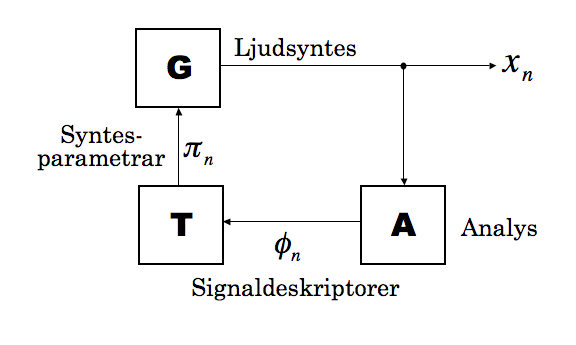
Signalgeneratorn är en oscillator, eller någon sammansatt syntesmodell som genererar en ljudsignal \(x_{n}\) vars egenskaper beror på syntesparametrar \(pi_{n}\), där \(n\) är tidpunkten räknat i sampel. Signalen \(x_{n}\) skrivs till en ljudfil (om man arbetar i realtid, vilket är fullt möjligt, så skickas signalen direkt via ljudkort till högtalarna) men den går också vidare till analysmodulen. Syftet med analysmodulen är att få fram olika signaldeskriptorer (ofta kallat feature extractors på engelska (Peeters et al., 2011)), som beskriver mer eller mindre perceptuellt relaterade egenskaper som grundton i Hz, spektral centroid, amplitud, grad av brusighet, osv. Analysmodulen förhåller sig hela tiden till ett visst utsnitt i tid av signalen, låt säga de senaste \(L\) samplena, och genererar en ström av signaldeskriptorer \(phi_{n}\). För enkelhets skull kan vi anta att signaldeskriptorerna genereras med samma samplingsfrekvens som ljudsignalen, så att analysmodulen kan skrivas som en funktion
\begin{equation} \phi_{n}=A\left(x_{n},x_{n-1},\ldots,x_{n-L+1}\right)\label{eq:FEFS_A} \end{equation} [1] där \(phi_{n}\in\mathbb{R}^{p}\) kan vara en vektor av p olika signaldeskriptorer som analyseras parallellt. Nästa steg är att omvandla denna dataström till en form som passar att använda som syntesparametrar. Om signalgeneratorn har q olika syntesparametrar måste transformatorn vara en eller annan funktion \(T:\mathbb{R}^{p}\rightarrow\mathbb{R}^{q}\) så att
\begin{equation} \pi_{n}=T(\phi_{n}).\label{eq:FEFS_T} \end{equation} [2] Signalgeneratorn, slutligen, genererar signalen [mathjax:inline x_{n}] på ett sätt som beror på det aktuella värdet av syntesparametrarna. Det är praktiskt att ta med en intern tillståndsvariabel \(theta_{n}\) också som kan representera fasen i en oscillator; den måste kommas ihåg till nästa gång generatorn ska generera ett nytt sampel. Då blir generatorn en funktion av formen
\begin{equation} \begin{array}{ccc} x_{n+1} & = & G(\pi_{n},\theta_{n})\\ \theta_{n+1} & = & \theta_{n}+f(\pi_{n}) \end{array}\label{eq:fefs_G} \end{equation} [3]
De tre ekvationerna (1, 2, 3) beskriver tillsammans ett dynamiskt system, eller rättare en stor klass av olika system. För nu måste de abstrakta ekvationerna ges konkret innehåll i form av specifika signalgeneratorer, deskriptorer och transformationer. Exempel på autonoma instrument som bygger på den här typen av system har jag beskrivit ingående i min avhandling och i några artiklar, så jag ska inte gå in på detaljer här.1
Det rör sig som sagt om en omfattande klass av dynamiska system, och det är svårt att sammanfatta alla egendomligheter man kan vänta sig att finna i sådana system. Här kan det vara värt att betona att det rör sig om deterministiska system där slumpmässigheter inte spelar någon roll.
Fysiker och matematiker har studerat långt enklare system än ovanstående FEFS-modeller, både länge och ingående. Starkt förenklade modeller har den fördelen att de lättare låter sig studeras och förstås än mera komplicerade och realistiska modeller. Jag har mestadels hållit mig till att göra empiriska, men systematiska studier av valda system. Utifrån mängder av mer eller mindre formella experiment har jag fått en viss intuition för vad slags typer av beteenden som kan uppstå. Det är till exempel enkelt att konstatera att längden L på analysfönstret har en avgörande effekt i praktiskt taget alla varianter av dessa system. Ett långt fönster betyder att man analyserar en lång portion av signalen vilket tenderar att jämna ut eventuella ojämnheter och plötsliga förändringar. Med kortare fönster följer man detaljer i signalen och det är lättare att åstadkomma vilda, brusiga, knastriga typer av ljud. Man kan nästan alltid höra en inledande transient innan systemet stabiliserar sig. Man skulle kunna tro att transientens längd är korrelerad med analysfönstrets längd, men det behöver inte alltid vara tillfället.
I en viss ganska komplicerad FEFS-modell uppträder transienter som kan vara extremt långa, upp till flera minuter, innan systemet så småningom stabiliserar sig på en uthållen ton. I vissa fall är det inte säkert ifall systemet någonsin kommer att nå det stabila tillståndet. Resultatet av ett experiment där jag lät systemet gå i upptill 20 minuter vid olika värden av en kontrollparameter framgår i figuren nedenfor. För vissa parametervärden får man kortvariga transienter, på under en minut, medan andra parametervärden strax intill kan leda till en process som håller på i över 20 minuter - det är ovisst om systemet någonsin stabiliserar sig i det fallet.
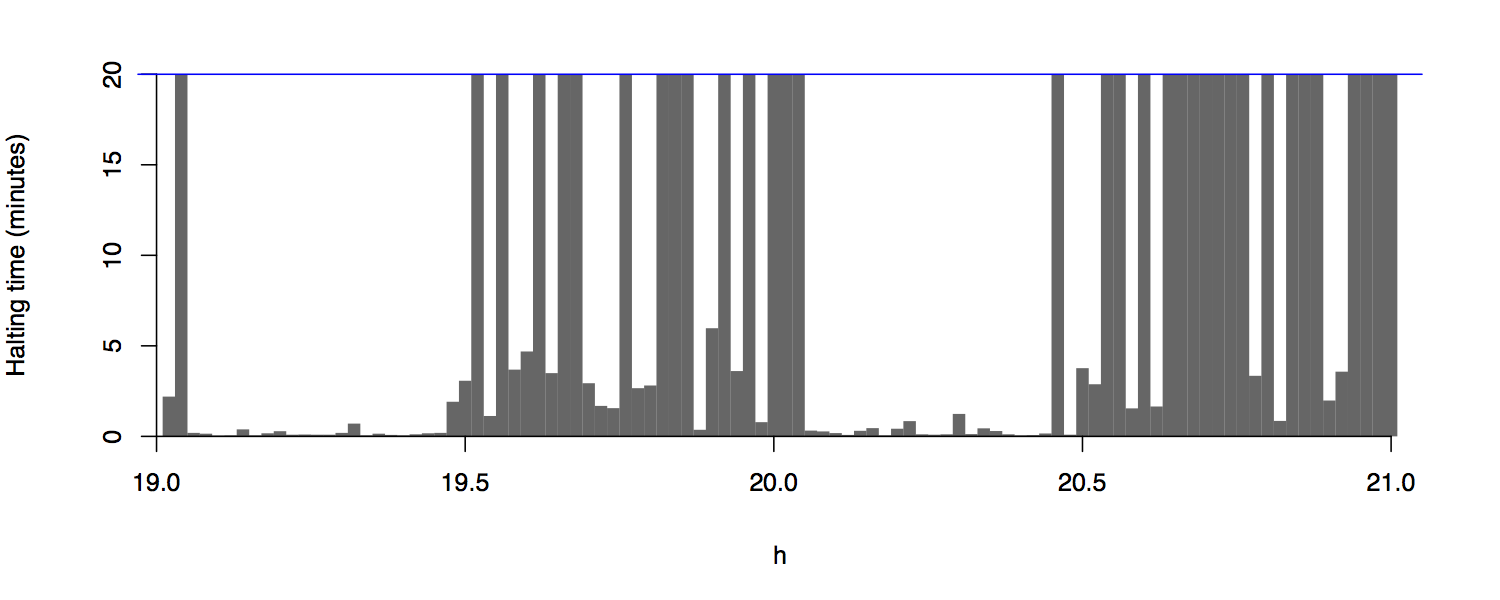 Transienternas längd i minuter som funktion av en kontrollparameter.
Transienternas längd i minuter som funktion av en kontrollparameter.
Systemet som ger upphov till dessa intressanta transienterna är relativt komplicerat och finns beskrivet i min avhandling (Holopainen, 2012, p. 255 ff). Det är befogat att fråga sig om inte samma slags fenomen kan uppstå i långt enklare system. Det kan mycket väl tänkas, men frågan är hur man i så fall ska förenkla systemet. Å andra sidan har det ofta hänt att de allra enklaste FEFS-modellerna inte uppvisar något anmärkningsvärt beteende, utan man måste lägga till ytterligare komplicerande mekanismer för att de ska börja bli intressanta.
Fysikern J. C. Sprott har systematiskt undersökt en lång rad dynamiska system i form av ordinära differentialekvationer och försökt finna de mest eleganta kaotiska systemen (Sprott, 2010). Begreppet elegans är inte självklart i rigorösa studier av dynamiska system, men Sprott definierar det ungefär så att ett system med färre variabler och enklare konstanter är mera elegant än ett med flera variabler och komplicerade konstanter. På så sätt har han kunnat automatisera sökandet efter enkla, eleganta kaotiska system. Något liknande skulle kanske kunna göras med FEFS-modeller. Vad gäller elegans kan man använda Sprotts kriterier, men om man dessutom är intresserad av musikaliskt gångbara resultat kommer man knappast undan att höra igenom alltsammans och göra sin egen bedömning.
Man kunde tänka sig att knyta antalet dimensioner i ett system till elegans, även om det är aningen missvisande. Vissa system med många dimensioner kan nämligen ges koncisa beskrivningar, till exempel om det finns någon sorts symmetrier som förenklar dem. En FEFS-modell har väldigt många dimensioner, närmare bestämt minst lika många som storleken L av analysfönstret (ett typiskt tal är L = 1000 sampel). I det fallet påverkas inte ekvation [1] av fönsterlängden, däremot kan kortare fönsterlängd göra systemet mera benäget att bli kaotiskt.
Som kriterium för vad som är ett lyckat autonomt instrument har jag satt att systemet ska uppvisa komplext beteende av något slag. Det låter sig motiveras av att system som bara landar på en stabil ton kan realiseras med enklare medel; dessutom är det inte mycket att överraskas av i så fall. För att få systemet att uppvisa mera komplext beteende behöver man utforma omvandlaren T så att små variationer i signaldeskriptorerna förstärks och orsakar större variationer i syntesparametrarna. Samtidigt bör variationerna inte förstärkas obegränsat, vilket bara leder till att systemet exploderar och kollapsar. Det är kaotiska system som har förutsättning att generera något av intresse.
Skrämselpropaganda
Norbert Wiener, grundaren av cybernetiken, var tidigt ute med att varna för farorna med högt utvecklad artificiell intelligens. Exemplet han ger i boken Cybernetics rör översättningsprogram och de risker det skulle medföra att lita på dem i kritiska situationer, till exempel om man vill avlyssna terrorister eller en fientligt inställd stat (Wiener, 1961).
I datormusik, och inte minst där maskinlyssning används kan man se en tendens mot ökande användning av artificiell intelligens och autonoma system. Det är kanske en harmlös domän för experimentering, även om det alltid har funnits de som har förfärats över att 'maskinerna tar över'. Man behöver inte längre kunna spela ett instrument (i betydelsen att öva upp motoriska färdigheter på hög nivå) för att kunna skapa musik. Färdigheterna har förflyttats från det motoriska till det mentala. Men lika lite som digitaltryck har utplånat torrnål som grafiskt medium har den elektroniska musikteknologin tagit död på de akustiska instrumenten. Frågan är bara hur långt vi är villiga att gå i automatiseringen av musikmaskiner.
Nick Collins program Autocousmatic2 är ett bra exempel på en automatiserad kompositionsprocess. Programmet läser in ett antal ljudfiler från en mapp och man ställer bara in önskat antal minuter och antal kanaler, så genererar programmet en akusmatisk komposition. Det enda avgörande valet man kan ta är vilka ljudfiler man lägger i mappen, men vad programmet gör med dem kan man på inget sätt påverka. Huruvida program som Autocousmatic kommer att bli populära bland tonsättare beror nog inte så mycket på kvaliteten av musiken, som på graden av medverkan på väg mot det färdiga resultatet. Jag tror alltså inte på att programmet skulle kunna vinna i popularitet genom att lyckas med att generera bättre musik, enligt något som helst kvalitetskriterium. Här är komponistens medverkan obetydlig, även om man kan påverka resultatet en del genom valet av ljudmaterial. Därför skulle det förvåna mig om Autocousmatic eller liknande program skulle visa sig bli vanliga kompositionsverktyg. De flesta tonsättare jag känner till nöjer sig inte med att så att säga skapa sin musik av färdiga byggsatser som de kan montera enligt anvisning och sätta sin signatur på. Men om man själv skapar programmet som automatiskt genererar musiken blir ägandeförhållandet ett helt annat, eftersom man kan försöka utforma programmet så att det gör något som man är intresserad av.
Komplementet till automatiskt genererad musik är artificiell lyssning. I själva verket har Collins byggt in något slags lyssnande instans i sitt program. Ett annat exempel på artificiell lyssning är en situation där ett simulerat ekosystem av sjungande fåglar genererar melodier (Todd & Miranda, 2006). Hanarna sjunger och honorna lyssnar. De hanarna som sjunger intressanta sånger får avkomma med honorna, och på så sätt utvecklas en musikalisk kultur genom genetiska algoritmer.
Om man vill bygga in musikaliska förutsättningar (till exempel att man ska hålla sig till ljud med urskiljbar tonhöjd, och till tolv tempererade tonhöjder i oktaven) i autonoma instrument, så kan man göra det. Men då begränsar man förstås också den möjliga musiken som de kan generera. Om det är en sorts omänsklig musik man vill komma åt borde man kanske lyssna på äkta fåglar, valar, delfiner och möss istället. Oavsett om man lägger in stilistiska premisser eller ej, så kan man räkna med en urvalsprocess där man väljer vilka resultat skapade med autonoma instrument man kan tänka sig att använda. Därför torde det vara svårt att komma undan existerande stilar i musik skapad med autonoma instrument, det vore helt enkelt att hoppas på för mycket. Den ryske cybernetikern Zaripov framhöll att det framtida, utopiska projektet för artificiell komposition inte bara skulle röra sig om imitation av existerande stilar, utan förutsägandet av nya stilar (Zaripov,1969). Helt omöjligt är det nog inte även om ingen förmodligen har lyckats med det än.
För att autonoma instrument ska kunna bli mera innovativa och gå utanför pålagda stilnormer krävs det kanske ett samarbete med lyssnare av ett nytt slag, artificiella lyssnare som har en annan sorts perception än mänskliga lyssnare. Där skulle vi kunna sluta cirkeln och låta de autonoma instrumenten spela för den artificiella publiken utan att vi behöver bry oss om vad de håller på med.
Referenser
Holopainen, R. (2012). Self-Organised Sounds with Autonomous Instruments: Aesthetics and experiments. PhD thesis, University of Oslo, Norway.
Mountain, R. (2001). Composers and imagery: Myths and realities. In Godøy, R. I. and Jørgensen, H., editors, Musical Imagery, chapter 15, pages 271–288. Swets and Zeitlinger.
Peeters, G., Giordano, B., Susini, P., Misdariis, N., and McAdams, S. (2011). The timbre toolbox: Extracting audio descriptors from musical signals. Jour- nal of the Acoustic Society of America, 130(5):2902–2916.
Sanfilippo, D. and Valle, A. (2012). Towards a typology of feedback systems. In Proc. of the ICMC 2012, pages 30–37, Ljubljana, Slovenia.
Sprott, J. C. (2010). Elegant Chaos. Algebraically Simple Chaotic Flows. World Scientific, Singapore.
Todd, P. and Miranda, E. R. (2006). Putting some (artificial) life into models of musical creativity. In Deliège, I. and Wiggins, G., editors, Musical Creativity. Multidisciplinary Research in Theory and Practice, chapter 20, pages 376–396. Psychology Press, Hove and New York.
Wiener, N. (1961). Cybernetics: or Control and Communication in the Animal and the Machine. The MIT Press, second edition.
Zaripov, R. K. (1969). Cybernetics and music. Perspectives of New Music, 7(2):115–154.
- 1. Avhandlingen och relevanta artiklar finns här: http://folk.uio.no/ristoh/adaptive.html
Ljudexempel på FEFS-modeller och liknande finns här: http://folk.uio.no/ristoh/adapt.sndex.html
Jag avstår i denna artikel från att diskutera egna kompositioner där jag har använt idéer relaterade till autonoma instrument, men det kan nämnas att försök i den riktningen har gjorts i vissa av styckena i verkcykeln Signals & Systems. Se http://folk.uio.no/ristoh/sigsys/signals_systems.html - 2. http://www.sussex.ac.uk/Users/nc81/autocousmatic.html